Anuario
de Psicología
1992,
n° 55, 7-22
© 1992,
Facultat de Psicología
Universitat
de Barcelona
Monica Bécue
Universidad
Politécnica de Cataluña
Ludovic Lebart
École Nationale
Supérieure de Télécommunications
Nuria Rajadell
Universidad de
Barcelona
Dirección de los autores: M. Bécue, Departamento de
Estadística e Investigación Operativa, Facultad de Informática, Pu Gargallo 5. 08028
Barcelona. Ludovic Lebart, Ecole National Supérieure de Télécommunications,
Département d'Economie. 46, rue Barrault, 75013 Paris. Nuria Rajadell,
Departamento de Didáctica y Organización Escolar, Facultad de Pedagogía,
Baldiri Reixac s/n, D, 4°. 08028 Barcelona.
Los investigadores se encuentran a
menudo enfrentados en la recogida de datos con información textual, sea a
través de las preguntas abiertas de una amplia encuesta, sea con entrevistas,
sea con otro tipo de textos de fuentes de datos secundarios. Tanto con finalidad
exploratoria o de clasificación previa como a la hora de comprobación de
determinadas hipótesis. Los métodos estadísticos constituyen una herramienta
importante para el tratamiento de textos. Especialmente permiten confrontar los
resultados obtenidos del análisis estadístico de textos con otras variables
estructurales procedentes de las grandes encuestas interviniendo como variables
ilustrativas. En este artículo presentamos un ejemplo sobre la opinión de 895
escolares del nivel de Educación Primaria (10-11 años) del Área Metropolitana de Barcelona, generada a
partir de la pregunta abierta «Para mí leer es...». Se muestran algunos
resultados proporcionados a través del tratamiento estadístico de análisis de
datos textuales, mediante el sistema informático SPAD-T.
Palabras
clave: Análisis
estadístico de textos, análisis de correspondencias, análisis multivariante.
The investigators can be confronted with textual
information, during data gathering, in large surveys, in interviews or in other
secondary sources. The Statistical Methods are useful and important tools in
dealing with texts, in exploratory aims or in a priori classifications, as well
as the verifying of certain hypothesis. Zn particular, it allows to confront
results obtained from text statistical analysis and other structural variables
coming from large surveys, being introduced as ilustrative variables. Zn this article
we present un example about the opinion of 895 students of the Primary School
(10-11 years old) on the Metropolitan Area of Barcelona, generated for the open
question «For me read is.». We present differents results obtained through
SPAD-T system.
Key words: Statistical Textual Analysis, Analysis of
Correspondances, Multivariate Analysis.
El
análisis de datos textuales
Los
métodos de la estadística textual han surgido del encuentro entre el estudio
cuantitativo de los textos literarios, por una parte, y la corriente de la
estadística moderna llamada análisis de datos, por otra.
Las
distribuciones lexicales, inicialmente descubiertas como leyes empíricas para
mejorar la transcripción estenografica, han sido posteriormente estudiada bajo
el lema de «psicobiología del lenguaje» (Zipf, 1946).
En
un segundo tiempo (Yule, 1944; Guiraud, 1960; Muller, 1968) la estadística
lexical se enfrentó con problemas planteados por estilistas preocupados por el
estudio comparativo del vocabulario de los «grandes autores»: comparación de la
riqueza del vocabulario, análisis de la evolución del vocabulario de un mismo
autor, etc. Esta corriente se vio reforzada por la difusión de los
computadores, y enriquecida
por los análisis de tipo morfosintáctico (según especifican por ejemplo
Bourques y cols., 1988).
Los
métodos de la estadística textual se aplican ahora a todo tipo de textos
transcritos sobre soporte informático. Por lo tanto, se pueden utilizar entre
otros métodos de aproximación a los textos (lingüística/análisis del discurso,
análisis de contenido, indexación automática, inteligencia artificial), en las
distintas disciplinas que entran en relación con el texto (historia, sociología,
psicología, etc.), teniendo en cuenta en cada caso, evidentemente, las
perspectivas de investigación propias de dichas disciplinas. Una parte
importante de los trabajos de investigación -que comporta aplicaciones
industriales considerables- se dedica a la comprensión de los lenguajes
naturales (obsérvese una síntesis en Coulon y cols., 1986).
Los métodos
del análisis de datos han probado, en lo que concierne a los estudios textuales
(Benzecri, 1981), su aptitud para elaborar tipologías mediante el recuento de
las formas gráficas. Dichos métodos presentan la ventaja de estudiar los
perfiles lexicales en su conjunto, y, por lo tanto, tomar en cuenta redes de
autocorrelaciones bastante finas. Así consiguen llegar bastante lejos en el
estudio de los textos, a la vez que guardan una total independencia de la
lengua tratada. Con el sistema informático SPAD.T (Lebart y cols., 1989)
utilizado para analizar el ejemplo presentado en este artículo, se han tratado
además textos en castellano, catalán, croata, francés, griego, inglés, italiano
y provenzal.
Las
preguntas abiertas
Las
preguntas abiertas son todavía poco utilizadas en las encuestas, porque la
explotación de las respuestas recogidas es difícil y costosa. No obstante, la
información obtenida mediante dichas preguntas puede ser muy distinta de la
obtenida mediante preguntas cerradas (Schuman y Presser, 1981); por lo tanto,
puede ser necesario mantener una pregunta abierta en razón de la información
buscada.
Citemos
dos situaciones-tipo bastante corrientes para las cuales la utilización de un
cuestionario abierto se impone. Para economizar el tiempo de entrevista (una
pregunta abierta puede sustituir una larga lista de opciones), y para explicitar
las respuestas a preguntas cerradas mediante el uso de la clásica pregunta
abierta «¿Por qué?» Las explicaciones relativas a una respuesta anterior se
deben dar de forma espontánea: proponer una batería de ítems podría ofrecer nuevos
argumentos y falsear la sinceridad de la explicación.
La
utilidad de este tipo de preguntas ha sido subrayada por numerosos autores y
solo las dificultades y el coste de explotación limitan su uso. Sin embargo, solo
una pregunta abierta permite saber si las distintas categorías de personas interrogadas
han entendido la pregunta cerrada de la misma forma; hecho particularmente importante
en las encuestas internacionales, porque permite detectar eventuales
divergencias semánticas introducidas por el enunciado de la pregunta en función
de la lengua utilizada.
No
podemos más que resaltar la importancia que posee la postcodificacion. Las
técnicas clásicas de postcodificacion operan construyendo una batería de ítems
a partir de una muestra de respuestas. Después se codifica el conjunto de las
respuestas de tal forma que se sustituye la respuesta abierta por una o mas respuestas
cerradas.
Para
respuestas simples, muy tipificadas y poco numerosas (dicho de otra forma: para
respuestas a una pregunta que se habría podido cerrar sin dificultad...) este
procedimiento presenta pocos inconvenientes. Para otros casos se pueden mencionar
rápidamente algunos de 10s defectos de este tipo de tratamiento: subjetividad de
la codificación, empobrecimiento de la forma y mutilación del contenido.
¿Qué unidades
estadísticas?
Cuando
la recogida de textos en soportes informáticos constituía la parte más
importante del tratamiento estadístico de los textos en ordenador, las
polémicas sobre la naturaleza de las unidades estadísticas fueron bastante
vivas. ¿Era indispensable, como afirmaban algunos, trabajar solo con textos
fuertemente sobrecodificados en categorías gramaticales, reduciendo los
plurales al singular, los verbos flexionados al infinitivo, etc., cosa que
entorpecía de manera notable la entrada de textos en computadores? ¿Se podían
empezar a tratar recuentos obtenidos de manera totalmente automática teniendo
en cuenta solo las formas graficas (relación de caracteres gráficos delimitados
por blancos o signos de puntuación), dejando para las etapas ulteriores del
análisis los problemas de falta de ambigüedad y de lematización?
Una aproximación más pragmática
Sin
profundizar en estas divergencias teóricas, el desarrollo reciente de la
informática aclara estas cuestiones con una nueva luz. En estos momentos la
grabación sobre soporte magnético se transforma en la forma más natural de
almacenar la información textual. El desarrollo de los lectores ópticos
facilita, cada día más, la recogida de textos impresos.
Así
pues, al tratamiento informatizado de textos brutos -considerados como una
sucesión de formas graficas- se le atribuyen nuevos objetivos, como la verificación
de la corrección de entradas automáticas, las tipologías de textos realizadas
en una primera fase con carácter exploratorio o la localización de las unidades
que funcionan en los textos agrupados en corpus, entre otras.
La
definición de la unidad de base debe merecer una reflexión especifica. En
efecto, para efectuar los recuentos utilizables por los algoritmos de análisis
de datos, es posible definir de formas muy distintas las unidades de la cadena
textual.
Formas gráficas y segmentos repetidos
La
unidad de base será la forma gráfica definida como una sucesión de caracteres
no delimitadores (normalmente letras) junto a caracteres delimitadores (blanco,
puntos, comas...). Una misma palabra podrá, en general, dar lugar a numerosas
formas gráficas, según su caso o genero gramatical en el texto; una misma forma
gráfica puede igualmente reflejar numerosas palabras. Esto no supone un gran
inconveniente, pues las formas graficas no serán tratadas aisladamente.
El
tratamiento integrado constara de dos aspectos: un aspecto multidimensional
clásico, que se interesara por los perfiles de frecuencias de formas gráficas,
es decir, por los vectores cuyos componentes equivalen a las frecuencias de cada
una de las formas utilizadas por un individuo o un grupo de individuos; conteniendo
estos perfiles una información extremadamente rica. El segundo aspecto, al que
se le califica de contextual, consiste en tomar en cuenta nuevas unidades
estadísticas, los segmentos repetidos (Salem, 1987). Se trata de secuencias de
formas simples que aparecen con cierta frecuencia y que enriquecen los perfiles
de formas y ayudan a aclarar ciertas ambigüedades de interpretación, en la cua1
interviene el contexto de estas formas.
Los
algoritmos particulares de cálculo permitirán descubrir dichos segmentos repetidos.
Precisando todavía más, las técnicas evidenciaran las diferencias entre perfiles
de formas gráficas y de segmentos.
Mientras
que la interpretación de un perfil puede ser delicada (p. ej. ¿por qué esta categoría
de entrevistados utiliza estas palabras con estas frecuencias?), la
interpretación de las diferencias es todavía más sencilla: sin especular sobre el
significado de los perfiles, se puede observar claramente que, por ejemplo, dos
categorías de entrevistados tienen unos perfiles próximos, alejados de los de
las otras categorías. Simplificando al máximo, se puede resumir esta
aproximación «por contraste o por diferencia» a través de la fórmula siguiente:
no es necesario saber lo que han dicho dos categorías para saber si han
expresado o no la misma opinión o concepto.
Para
seleccionar formas y segmentos es imprescindible utilizar umbrales de
frecuencia, los cuales permitirán efectuar filtros a diferentes niveles sobre
la información de base. Esta fase de tratamiento preliminar consiste en
destinar a cada nueva forma gráfica un numero de orden que será asociado a
todas las ocurrencias de esta misma forma. Estos números serán almacenados en
un diccionario de formas, o vocabulario, propio de cada explotación, el cua1
permitirá, a la salida de los cálculos o de las impresiones, reconstituir el
grafismo de las formas evidenciadas a través de los cálculos estadísticos.
Una
etapa intermediaria de tratamiento podría consistir en «lematizar» el
vocabulario (p. ej. declarar equivalentes las formas graficas correspondientes
a una misma palabra) o depurar este vocabulario de palabras-herramientas
(artículos, conjunciones, etc., véase por ejemplo Reinert, 1986).
La
experiencia obtenida en el análisis de preguntas abiertas demuestra que esta
etapa no es del todo indispensable, o que no debe intervenir demasiado pronto.
Las formas gráficas diferentes de una misma palabra pueden estar relacionadas
con un contexto y un
contenido particular, y algunas palabras-herramientas pueden caracterizar de
una manera concreta actitudes u opiniones.
Tablas de contingencia léxicas
Los
métodos de análisis de datos suelen tratar grandes tablas de datos creadas a
partir de variables nominales, ordinales o cuantitativas. Para aplicar estos
métodos -en particular el análisis de correspondencias y
los métodos de clasificación-
a las respuestas abiertas, se construyen tablas de contingencia particulares:
1. La
tabla léxica contiene la frecuencia con la cua1 una forma gráfica es empleada
por cada uno de los individuos. El análisis de correspondencias, aplicada esta
tabla de frecuencias, llamada tabla léxica, procede por comparación de las distribuciones
de las formas en los individuos, es decir compara los perfiles léxicos de los
individuos.
2. Si
existen una o varias particiones pertinentes del corpus -partición del corpus
en grupos de respuestas según la clase de edad del individuo, según el sexo- se
puede construir la tabla de contingencia que contiene la frecuencia de cada forma
en cada parte del corpus. Esta tabla se llama tabla léxica agregada.
3. Se obtienen tablas similares
sustituyendo las formas por los segmentos repetidos. En una tabla de
contingencia, las filas y las columnas representan dos particiones de una misma
población y ambas particiones juegan un papel análogo: para analizar el
contenido de la tabla tiene sentido considerar tanto la nube de puntos-fila
como la nube de puntos-columna. El análisis de correspondencias ofrece una
representación gráfica conjunta de ambas; para ello efectúa la proyección de
las nubes sobre subespacios de dimensión reducida, pero manteniendo la máxima
dispersión posible.
El
análisis de correspondencias aplicado a las tablas léxicas proporciona una
visualización de las similitudes entre perfiles de frecuencias de formas. El
análisis de las tablas segmentales permite, además, tener en cuenta el orden en
el cua1 aparecen las formas.
El análisis de datos textuales aplicado a
la investigación educativa
Con el
fin de conocer la opinión sobre la lectura que poseen los escolares del nivel
de educación primaria, se ha realizado una amplia investigación en el área
metropolitana de Barcelona. Para medir las actitudes lectoras a través de las
cuatro facetas consideradas configuradoras de dichas actitudes -personales,
familiares, escolares y ambientales-, se pueden aplicar diferentes instrumentos
con enfoques desde lo más cuantitativo hasta lo más cualitativo. Pero nos
interesan de una manera especial dos de los cuestionarios elaborados en el
curso de dicha investigación (Rajadell, 1990), para poder caracterizar las
actitudes lectoras; uno de ellos pretende de manera específica conocer las
actitudes a partir de una escala tipo Likert con cinco posibilidades de
respuesta; el otro, mucho más amplio, pretende recoger, de manera general, la
máxima información en torno a los hábitos, intereses y realidades relacionados
con la lectura. En este último se encuentran dos preguntas de carácter abierto
con los siguientes enunciados:
1. Para mi
leer es...
2. Creo que leer es
importante porque ...
La
primera pregunta facilita el conocimiento sobre el concepto de lectura que
poseen los escolares, mientras que la segunda cuestión nos informa sobre la
importancia que otorgan al acto y efecto de leer.
La
muestra estudiada está formada por 895 alumnos y alumnas que están cursando
quinto curso de EGB, con una edad de 10-11 años, cuya proporción está
configurada por un 51.2 % de
niños y
un 49.6 % de niñas, asegurando la
presentación de la variable sexo con un respetable equilibrio. Este alumnado se
encuentra ubicado en
centros escolares de variada tipología (públicos 56 % y privados 34 %).
Por otra
parte, los niños contestan a un amplio cuestionario que incluye preguntas sobre
su actitud hacia la lectura. La consulta de las fichas escolares ha permitido
obtener, además, variables-indicadoras de la situación socioeconómica de sus
familias.
En este
articulo presentaremos algunos resultados proporcionados por el tratamiento
estadístico de la primera pregunta abierta, utilizando métodos estadísticos de análisis
de datos textuales.
Métodos de análisis
Mediante
el tratamiento del cuestionario presentado se pretenden ilustrar las
principales etapas del análisis de una encuesta que incluye preguntas abiertas y
cerradas.
Una
etapa preliminar permite reagrupar a los escolares en clases homogéneas en
cuanto a las características socioeconómicas de sus familias. Para dicho reagrupamiento
se emplea la técnica llamada de «Núcleos factuales» (Lebart y Salem, 1989). No
es posible extenderse aquí sobre este método que permite obtener reagrupamientos
operativos de centenares o millares de individuos en un número reducido de
clases, teniendo en cuenta las respuestas a un grupo de variables, así como sus
interrelaciones. En este ejemplo, se tienen en cuenta las respuestas a las
variables indicadoras de la situación socioeconómica.
Una vez
eliminados del estudio los escolares de los cuales no se poseen estos indicadores
-restando un global de 857 individuos- se han obtenido seis clases de
escolares. La Tabla 1 describe
las clases, de forma precisa, mediante la comparación de los porcentajes de
respuestas internas en cada clase y de los porcentajes globales con el fin de
seleccionar las modalidades más características. Se puede observar que ciertas
modalidades ilustrativas (es decir, no utilizadas para la construcción de las
clases) son repartidas de forma diferenciada en las clases.


Glosario
de formar y segmentos repetidos
La Tabla
2 muestra las 109 formas repetidas al menos 8 veces en el corpus formado por
las respuestas a la primera de las dos preguntas abiertas de los 857 individuos
que configuran la población. La forma más frecuente es «y». La
forma llena más frecuente es «divertido».
Las formas «importante»
y «aprender» aparecen
a continuación.
Las
formas-herramientas tienen el mismo tratamiento que las formas llenas. Si su
distribución en las respuestas es aleatoria no perturban los resultados. Si,
por el contrario, su distribución no es debida al azar aportan una información interesante.
De la misma forma, si dos formas graficas referidas a la misma palabra -las
diferentes formas del verbo «aprender»
por ejemplo-, tienen un comportamiento similar, se pueden sustituir
por la misma palabra, si no se refieren a usos diferenciados de la misma
palabra.
La Tabla
3 muestra
los segmentos observados en las respuestas abiertas, segmentos seleccionados
por umbrales de frecuencia: los segmentos formados por dos palabras empleados
al menos 30 veces, por tres palabras empleados al menos 10 veces y los más
largos empleados al menos 5 veces.


Construcción
y análisis de correspondencias de una tabla léxica agregada
Las
respuestas de los escolares son reagrupadas en función de la clase de pertenencia
del escolar, obtenida anteriormente. Se construye la tabla léxica agregada que
contiene la frecuencia con la cua1 cada grupo emplea cada una de las 109 formas
conservadas. Para el análisis de correspondencias, se considera la clase 4
como un elemento
ilustrativo: en efecto, los escolares de esta clase no han contestado a
numerosas preguntas cerradas y sus respuestas abiertas son extremadamente estereotipadas.
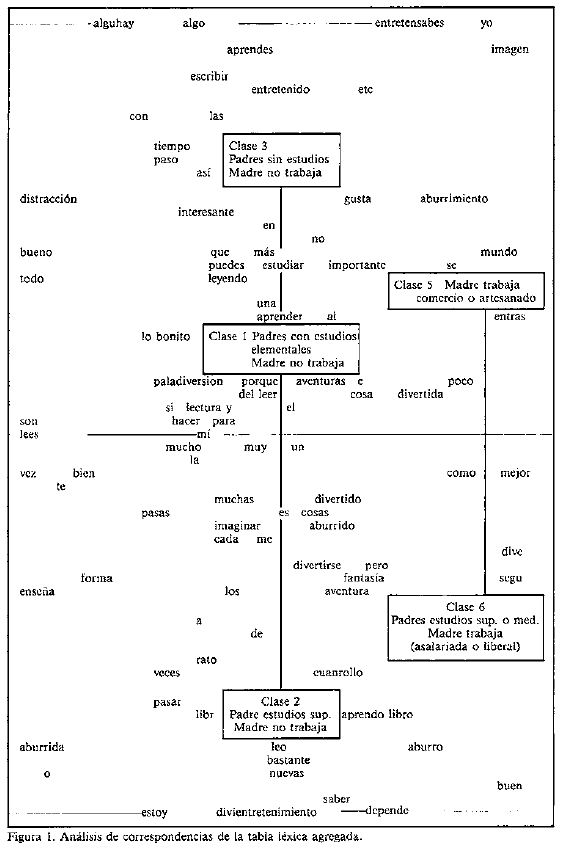
En la Figura 1, se
presenta el primer plano obtenido mediante el análisis de correspondencias de
dicha tabla.
El
primer eje opone las clases 5 y 6, caracterizadas por el trabajo de la madre, a
las otras clases. El segundo eje opone las familias de clase baja (clases 3 y 1
sobre todo, con padres sin estudios o con estudios elementales) a las familias de
clase media (clases 2 y 6, padres
con estudios medios o superiores): configura un eje socioeconómico. Que las
diferentes actitudes hacia la lectura, expresadas en la respuesta abierta,
estén relacionadas con la pertenencia a una u otra clase socioeconómica no es
sorprendente. Puede parecer más inesperada la relevancia que tiene el trabajo
de la madre en cuanto a la actitud lectora: el primer eje está constituido por
la oposición entre las clases de escolares cuya madre trabaja y las otras
clases.
Selección
de formas y segmentos característicos
Se puede
completar la representación gráfica obtenida por la selección de las formas más
características de cada una de las 5 clases. Esta selección, apoya da sobre
criterios probabilistas, detecta las formas «anormalmente» frecuentes en las
respuestas de un grupo de individuos. Para facilitar la lectura de la
caracterización de un grupo por una forma, se asocia a cada forma un valor-test
que mide la diferencia entre la frecuencia de la forma en el grupo y la
frecuencia de la misma forma en la población. Dicho valor-test esta normalizado
de tal forma que se pueda leer como una realización de una variable normal
centrada y reducida, bajo la hipótesis de repartición aleatoria de la forma
considerada en las clases. Por 10 tanto, se declaran características de una
clase de formas cuyo valor-test asociado es mayor que 1.96 (formas sobre representadas
en la clase) o menor que -1.96 (formas subrepresentadas en la clase). En la
Tabla 4,
se muestran las formas
características positivas de las clases 1 y 5 que son las clases situadas al mismo
nivel sobre el eje 2 y
opuestas sobre el eje 1. En
la Tabla 5 se muestran los segmentos característicos de esas mismas clases,
ampliados a través de la Tabla 6.



Selección de las respuestas modales
La
selección de las respuestas modales de las distintas clases (Lebart, 1982)
permite extraer respuestas reales tales que su vocabulario sea representativo
de vocabulario especifico de dicha clase. Dado un grupo de individuos, se puede
calcular el perfil léxico medio del grupo a partir de los perfiles léxicos de
los individuos que lo componen. Se pueden considerar como características de un
grupo las respuestas más próximas a este perfil medio, próximas en el sentido
de la distancia de Chi-2, distancia entre distribuciones de frecuencias ya
utilizada en el análisis de correspondencias. Se pueden, también, seleccionar
las respuestas características siguiendo otro criterio, el criterio del
valor-test medio. Según hemos visto en el párrafo anterior, se asigna a cada
forma y para cada grupo un valor-test que califica la significación de su
frecuencia en el grupo comparada a su frecuencia en la población. Se puede
atribuir a cada respuesta la media de los valores-test de las formas que la
componen. Las respuestas con valor medio más alto serán las más características
del grupo. La Tabla 6 muestra las respuestas modales de
la clase 1 obtenidas mediante la utilización de los dos criterios.
Discusión
Los
tratamientos posibles son más numerosos que los que hemos propuesto a partir de
este ejemplo, sin embargo, hemos pretendido a través de e1 explicitar básicamente
la especificidad de los métodos empleados. La aproximación estadística al
análisis estadístico de los datos textuales presentado a través de este articulo
ofrece una nueva lectura de los textos, lectura esencialmente distinta y a su
vez complementaria con la lectura analizada desde un enfoque mucho más manual.
Dicha lectura proporciona una descripción cuantitativa, sistemática y exhaustiva
del vocabulario. Ofrece una aproximación comparativa: se describen, analizan e
interpretan las diferencias entre los textos, entre los grupos de individuos.
Los
datos de encuesta constituyen el terreno de elección de estos métodos. Ante una
pregunta abierta concreta y dados diferentes grupos de individuos se pueden
obtener, sin ninguna precodificación previa, las características principales de
las diferencias entre los grupos. La visualización de las proximidades entre formas
y
categorías, mediante
el análisis de correspondencias de la tabla léxica agregada y/o de la tabla
segmental agregada, proporciona un resumen de las similitudes entre los grupos
y una descripción de la asociación entre palabras.
También
se pueden analizar con provecho otro tipo de textos -textos literarios, discursos
políticos, entrevistas no directivas ...-. El corpus constituido, sin embargo,
debe presentar un cierto grado de homogeneidad y de exhaustividad. Los resultados
obtenidos facilitan entonces la construcción de hipótesis y orientan los análisis
posteriores.
Referencias
Actes de les Jornades d´Analisi de Dades Textuals, Barcelona, 10-12. diciembre 1998,
Facultat d'Informatica de Barcelona, Universitat Polittcnica de Catalunya.
Editores: Bécue, M., Lebart, L. y Rajadell, N., Servei de Publicacions de la
UPC. Barcelona, 1992.
Bécue,
M. (1991). Análisis Estadístico de
Datos Textuales: Métodos de Análisis y Algoritmos. Paris: CISIA.
Benzécri,
J.P. (1973). La taxinomie, Vol.
I, L'Analyse de Correspondances, Vol.
11. Paris: Dunod.
Benzécri,
J.P. (1981). Pratique de IXnalyse
des Données, tome 3, Linguistique et Lexicologie. Paris: Dunod.
Bourques,
G. & Duchastel, J. (1988). Restons
Traditionnels et Progressifs. Pour lme Nolivelle Analyse du Discours Politique.
Montreal: Boréal.
Coulon, D. & Kayser, D. (1986). Informatique et
Langage Naturel: Présentation Générale des méthodes d'interprétation des
Textes. Techniques et Sciences
Znformatiques. Vol. 5, 2, 103-128.
Brian, E. (1984). Analyse des Données Lexicométriques.
Rapport Cred0dD.G.T.
Guiraud,
P. (1960). ProblCmes et Méthodes de
la Statistique Linguistique. Paris: PUF.
Haeusler,
L. (1984). Analyse Lexicale de
Réponses Libres: Le Coi2 de I'Electricité. Rapport Crédoc-EDE
Lafon,
P. & Salem, A. (1983). ctl' Inventaire
des Segments Répétés d'un Texte,,, Mots,
6, 161-177.
Lebart,
L. (1982). L' Analyse
Statistique des Réponses Libres dans les EnquEtes Socio-économiques. Consornmation, I, pp. 39-62,
Paris: Dunod.
Lebart, L., Morineau, A. & Warwick (1984). Multivariate Descriptive Statistical
Analysis. New York: J. Wiley
and
Lebart, L. & Salem, A. (1989). Analyse
Statistique des Données Textuelles. Paris: Dunod.
Lebart, L., Morineau, A. & Bécue, M. (avec la
coll. de P. Pleuvret et L. Haensler) (1989). SPAD.'I: Systeme Portable pour IHnalyse des Données
Textuelles. Manuel
de Références., Paris: CISIA.
Muller,
C. (1968). Initiation a la Statistique Linguistique. Paris: Larousse.
Rajadell,
N. (1990). Les Actituds envers la lectura. Un model dHnalisi per a
I'Educacid Primaria. Tesis doctoral no publicada. Universitat de Barcelona.
Rajadell,
N. (1991). El análisis de datos en la investigaci6n educativa. Lectura y
Vida, 12, 4, 31-40.
Reinert,
M. (1986). Un Logiciel dlAnalyse Lexicale. Les Cahiers de IHnalyse des
Données, 4, 471-484. Paris:
Dunod.
Salem,
A. (1982). ctAnalyse Factorieiie et Lexicométrie. Synthkse de Quelques
expiriences)), Mots, 4, 147-168.
Salem,
A. (1987). Pratique des Segments Répétés, Essai de Statistique Textuelle. Paris:
Klincksicck.
Schuman, H. & Presser, E. (1981). Question and
Answeris in Attitude Surveys. New York: Academic Press.
Yule, G.U. (1944). A Statistical Study of
Vocabulary. Cambridge University Press.
Zipf, G.K. (1935). The Psychobiology of Language,
an Introduction to Dynamic Philology.
Boston: Houghton-Mifflin.
Comentarios